Object-based classification of point clouds
Augmenting 3D geometry with semantic information
Can object-based classification of point clouds offer an alternative to classification of individual points when detecting and analysing natural landscape objects?
Today, the analysis of 3D point clouds acquired with topographic Lidar or photogrammetric systems has become an operational task for mapping and monitoring of infrastructure and environmental processes. Numerous applications require the identification and delineation of landscape objects and their properties. So far, many software solutions have been focused on the analysis of constructed and man-made objects, which are characterized by a regular and well-defined geometry (e.g. buildings, roads and other infrastructure). In comparison, the detection and analysis of natural landscape objects is challenging, since object boundaries might be fuzzy and the object characteristics within one class can be very diverse. This article explores the potential of object-based classification of point clouds as an alternative to classification of individual points.
In contrast to image or voxel data, point clouds usually have irregularly distributed point patterns and thus lack a regular basic unit. Therefore, local relations between neighbouring points have to be established as a first step. Many different variants of object-based workflows exist. The key steps of a typical object-based workflow for point cloud classification are (i) the segmentation of the point cloud, (ii) the calculation of segment features, and (iii) the classification of segments based on their feature values to label the objects of interest.
Point cloud segmentation
In the segmentation step, the point cloud is partitioned into subsets of neighbouring points called ‘segments’. In addition to neighbourhood definitions, further characteristics, such as spectral values and geometric features, are used for guiding this process. The result is a set of internally homogeneous segments, i.e. groups of points representing the basic units for classification. In many cases, segmentation procedures aim to produce relatively small segments, representing only object parts (sub-objects) in the first step rather than the final objects of interest directly. Once these segments are classified, adjacent segments of the same class can be merged to spatially contiguous objects. Such a step-wise procedure based on initial oversegmentation has proven to be beneficial as it reduces the risk of combining multiple real-world objects in one segment (undersegmentation).
Point features versus segment features
Depending on the target classes, the classification relies on features that characterise the different classes well enough for distinct separation, i.e. the classes must have a unique signature in the feature space, with sufficient differences between classes. Features on a point basis can, on the one hand, originate directly from sensor measurements, such as colour from imagery or corrected Lidar intensity. On the other, geometric point features can be extracted from the neighbourhood of the point. The neighbour search can be constrained either by a fixed number of neighbour points or by a defined search radius (for a cylinder or sphere). For the given neighbourhood point set, such features can describe the local point density, height distribution or deviations from a locally fitted plane, for instance. Moreover, eigenvalue-based features, derived from the point sets’ 3D covariance matrix, are often used, such as the omnivariance as a descriptor for the shape of the points’ distribution in 3D space.
In contrast to per-point classification, object-based classification exploits features that relate to segments (sub-objects). Such segment features can be the average or the standard deviation of all point-specific feature values in a segment. These segment features are often more representative for class characteristics than single point features, which can be very variable within a class and even within one object. Additional features, like segment shape and size, may also be useful to separate classes.
Classification of segments
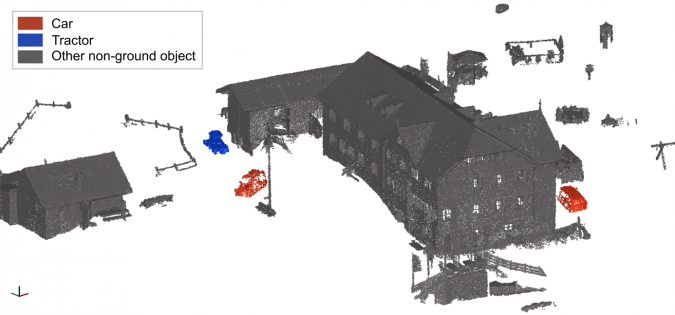
In the classification step, the (sub-)objects (i.e. segments) are assigned class labels based on their characteristic feature values. Figure 1 shows a simple example for object-based classification of vehicles in a point cloud acquired by a Lidar unmanned aerial vehicle (UAV). Here, all non-ground segments have been classified based on only two features: their mean Lidar reflectance and their mean omnivariance. First, individual people and small objects are filtered out by an object size threshold, then the segments are grouped into classes by k-means clustering with these features. Finally, semantic labels (‘car’, ‘tractor’, ‘other non-ground objects’) are assigned a posteriori to these classes.
While such simple unsupervised classification approaches might work for a small and very basic classification problem, various supervised classification algorithms are available for more challenging tasks. In supervised approaches, a statistical classifier is ‘trained’ with a limited number of representative sample segments with known class labels. This ‘training subset’ has often been labelled manually or using existing ancillary datasets. Finally, this classifier is applied to label all segments, depending on their feature values. In this respect, the segmentation can reduce the number of data entries to be classified by several magnitudes (e.g. from several million points to a few thousand segments). This improves the scalability of computationally expensive machine-learning algorithms for the classification of large point clouds, for instance.

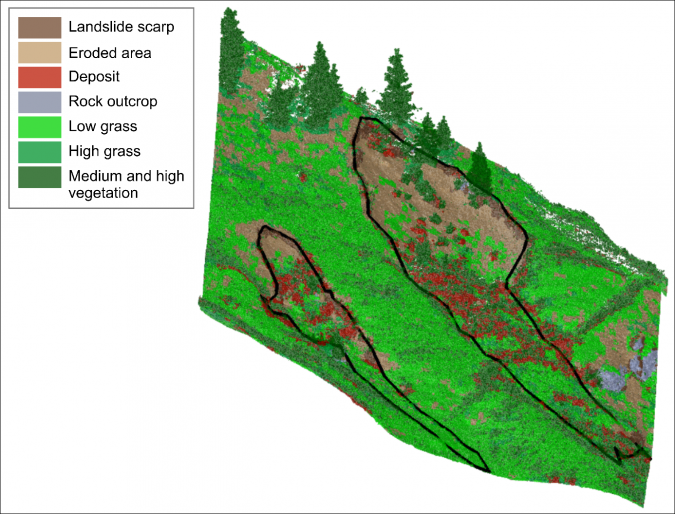
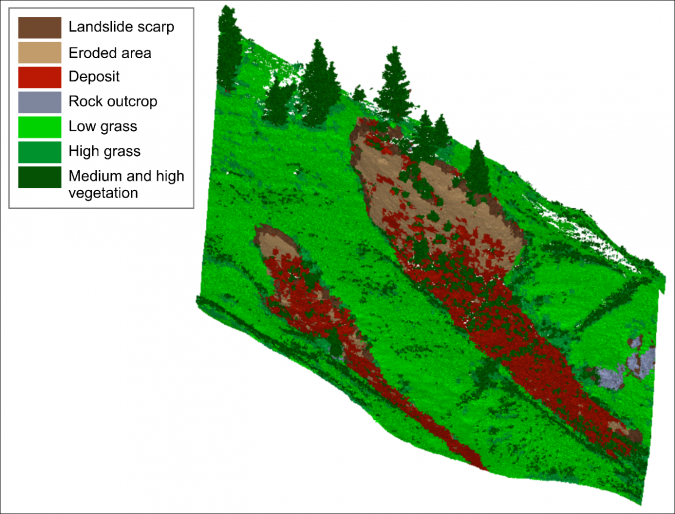
Probably the most important advantage, however, is the ability to model context in terms of a spatial relationship (topology) between objects. By taking into account objects of different scale levels, hierarchical relationships between objects and sub-objects can be established. Such topological relationships can, for instance, be used to correct misclassifications by applying topological rules. Figures 2-4 (and this video) show an example from landslide monitoring in a complex natural scene, using repeated terrestrial laser scans (TLS). Here, a machine-learning algorithm detects landslide-affected areas in 3D point cloud segments separated from stable slope areas and vegetation, based on geometrical features. After the classifier had been trained on a subset of segments from one scan epoch, it was used to classify the entire time series, which currently consists of 13 scan epochs. The ‘medium and high vegetation’ class was accurately classified in this step. However, the geometrical similarity between ‘eroded area’ and ‘low grass’ as well as between ‘high grass’ and ‘deposit’ makes their correct classification difficult. Thus, a simple topology relates the pre-classified segments to coarsely detected landslide outlines from each epoch, i.e. objects at a higher hierarchical level (super-objects). Reclassification by rules considering spatial context (e.g. ‘no eroded area outside the landslide outline’) improved the classification accuracy for certain classes by up to 14%. This example shows how object-based point cloud analysis for natural landscape objects can be used for applications in 3D deformation monitoring, automated interpretation of deforming objects and the identification of underlying geomorphological processes.
Advantages and challenges
It can be concluded that object-based classification of point clouds, i.e. using segments as the base unit for classification, is a promising alternative to classification of individual points. While generalising over noise and outliers in feature space, the geometric detail and accuracy of the original 3D point cloud is preserved for use in further analyses, such as deformation calculations. In addition, object-based approaches have the advantage of providing more informative features and contextual relationships for classification and object interpretation.
One of the most crucial steps in the approach is achieving a valid segmentation. This should keep points from different target objects separated, but at the same time create segments that are sufficiently large to provide meaningful additional features, such as segment size or shape and spatial context. The analysis of natural objects is especially challenging, since object definitions are sometimes ambiguous and gradual transitions exist at object boundaries. This approach provides an innovative way to tackle these challenges and to improve monitoring of objects in a natural environmental context.
Further reading
Mayr, A., Rutzinger, M., Bremer, M., Oude Elberink, S., Stumpf, F. & Geitner, C. (2017): Object-based classification of terrestrial laser scanning point clouds for landslide monitoring. The Photogrammetric Record. Vol. 32(160), pp. 377-397. DOI: https://doi.org/10.1111/phor.12215
Mayr, A., Rutzinger, M. & Geitner, C. (2018): Multitemporal analysis of objects in 3D point clouds for landslide monitoring. The International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences, Volume XLII-2, 691-697, https://bit.ly/2RD1LT5. (PDF)

Value staying current with geomatics?
Stay on the map with our expertly curated newsletters.
We provide educational insights, industry updates, and inspiring stories to help you learn, grow, and reach your full potential in your field. Don't miss out - subscribe today and ensure you're always informed, educated, and inspired.
Choose your newsletter(s)