What Do BIM, GIS, IoT, BMS, Telemetry and CAD All Have in Common?
Over the last three years, building information modelling (BIM) has undergone rapid development around the world. The value chain of design, construction and operation of built assets faces various challenges of change, some of which are of a technological nature. These include the transition from drawing in 2D to modelling in 3D with object reference and linked information. There is also an explosive increase in the volume of data on projects, including from new recording methods such as unmanned aerial vehicles (UAVs or ‘drones’), lasers, geo-radars, and the increased use of sensors and data transfer devices on the Internet of Things (IoT). As that data comes in so many shapes and sizes, there are continual efforts to enable interoperability. In connection with integration, we need to ask ourselves: what do BIM, GIS, IoT, BMS, telemetry and CAD all have in common?
Firstly, let us explore what exactly ‘interoperability’ means. The interoperable approach uses a fixed schema, which enables the theoretical bi-directional exchange of data between two compliant applications. However, the approach has proved unreliable at both data exchange and bi-directional support due to technical compliance by large software vendors and the complexity of setting up such tools.
Therefore, we should perhaps be more concerned with data integration which connects a superset schema to enable all data to be exchanged, whatever it may be. This is especially attractive in this area of engineering due to its complexity and the ever-expanding need to incorporate other contextual data to add operational and service value to asset information.
In connection with data integration, we need to ask ourselves what BIM, GIS, IoT, BMS, telemetry and CAD all have in common. The answer: they are no ordinary data; they all benefit from being geolocated in some way. Many professionals in the world of GIS have long understood the benefits of geolocation. In engineering, on the other hand, the approach to geolocation has often been from the microscopic perspective of the asset being built relative to itself, rather than relative to the wider world or city view.
This micro/macro perspective is interesting as it starts to provide context for the challenges of integrating geolocated information. At first glance, it looks easy. After all, there are only so many types of location methods. We can map from one to the other, so geolocation must surely provide the ultimate primary key to all data in the world, right? Well, maybe, but is this really true?
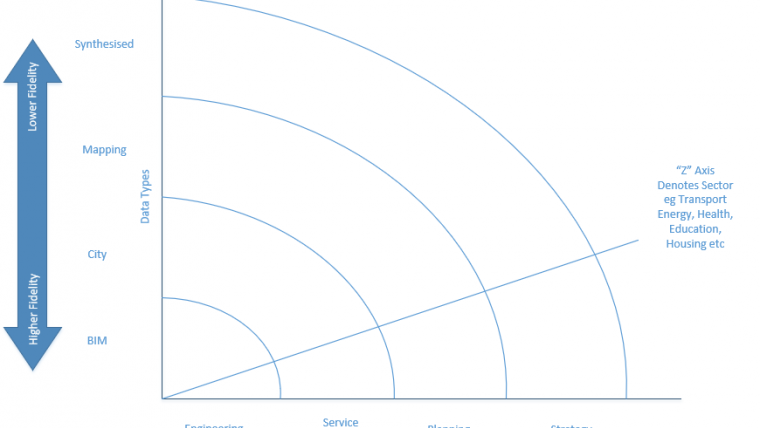
The issues of grids (including snakes), topology, moving grids and planets not being as round as we would like are all interesting, well-known and well-documented challenges in the GIS community. A less-discussed wider challenge is: even if we did geolocate all of the data types described above, what could we do with that information? And how does the state and fidelity of the data affect its ability to be used safely for which purposes? The figure shows a number of different data types and potential uses.
This illustrates how each part of the vast community involved in the built and natural environment has developed an ecosystem that is suited to its needs. Engineering and architecture are moving towards an integrated world of geometry and data, described by objects. The accuracy of the geometry can be to several decimal places; however, the typical tolerance of construction can be up to 50mm. As we move along the axis and reduce the fidelity of data, the use cases change: from service provision to planning and strategic purposes. Data also has a temporal component; it ages as the asset ages. Briefing data is very different from handover data, and sensor data provided by the emergent IoT world offers yet another dimension.
This leaves us with another fascinating question: which piece of data is correct, and how do I know I have that piece of data in front of me to solve my current problem? Data provenance and state are two concepts we have not heard about much to date. But get ready… you soon will.


Value staying current with geomatics?
Stay on the map with our expertly curated newsletters.
We provide educational insights, industry updates, and inspiring stories to help you learn, grow, and reach your full potential in your field. Don't miss out - subscribe today and ensure you're always informed, educated, and inspired.
Choose your newsletter(s)